NodeToCode
An Unreal Engine plugin that uses LLMs to translate Blueprint graphs into C++, C#, pseudocode, and other languages, streamlining optimization, learning, communication, and documentation.
00

problem
While powerful for rapid prototyping, complex Blueprint systems often become collaboration hurdles, performance bottlenecks, or documentation nightmares, with manual C++ conversion being a slow, tedious, and error-prone process.
solution
Node to Code intelligently analyzes Blueprint graphs, uses a custom LLM-friendly serialization format, and integrates with various AI providers (cloud or local) to automate the initial 80% of Blueprint-to-C++ translation, accelerating optimization and improving learning and communication workflows.

Introduction
After nearly a decade working deep within Unreal Engine across an almost absurd range of projects – from MR apps like Swing Genius and Cyberpunk for The Academy Museum to cutting-edge Virtual Production tools for Epic Games, immersive concerts for Sony Music, and even designing the #1 selling Vision Pro accessory – I've developed what some might call an obsessive appreciation for Blueprint visual scripting. It's been my go-to for rapid prototyping, allowing me to bring complex ideas to life at incredible speeds.
But there’s a paradox. The very tool that enables such rapid iteration often hits a wall as projects scale. I've felt this pain firsthand.
The Blueprint Bottleneck
On Swing Genius, over 95% of the Quest 3 app was built in Blueprints – sophisticated MR tracking, physics interactions, backend integration, even custom networking. It worked beautifully... until certain complex calculations or data processing loops started eating into our frame budget. On the Virtual Production tools I helped implement for UE 4.26 and 5.3, the visual nature was great for UI state management, but explaining complex Blueprint logic to engineers or documenting intricate flows became a major time sink involving endless screenshots and walkthroughs.
Then there was my pet project trading bot app. Integrating Kraken's API via Blueprint-callable C++ functions was fantastic for rapid strategy iteration. But processing thousands of historical data points through nested Blueprint loops brought performance to its knees – my first stark reminder of Blueprint's performance ceiling. I even pushed Blueprints to their absolute limits attempting things like real-time ray-traced light probes and reinforcement learning systems, inevitably hitting performance walls that demanded C++ conversion.
Manually translating these proven, working Blueprint systems felt like paying a hefty tax. It involved constant context switching between the Blueprint editor, IDE, documentation, and forum posts. Ensuring Blueprint compatibility (BlueprintCallable, BlueprintNativeEvent, etc.) and adhering to project conventions added layers of complexity. Explaining the logic to others often felt like giving an architecture tour through a house of cards. The very tool that accelerated my design process became a barrier to optimization, scalability, and collaboration. I needed the speed of Blueprints but the performance and maintainability of C++.
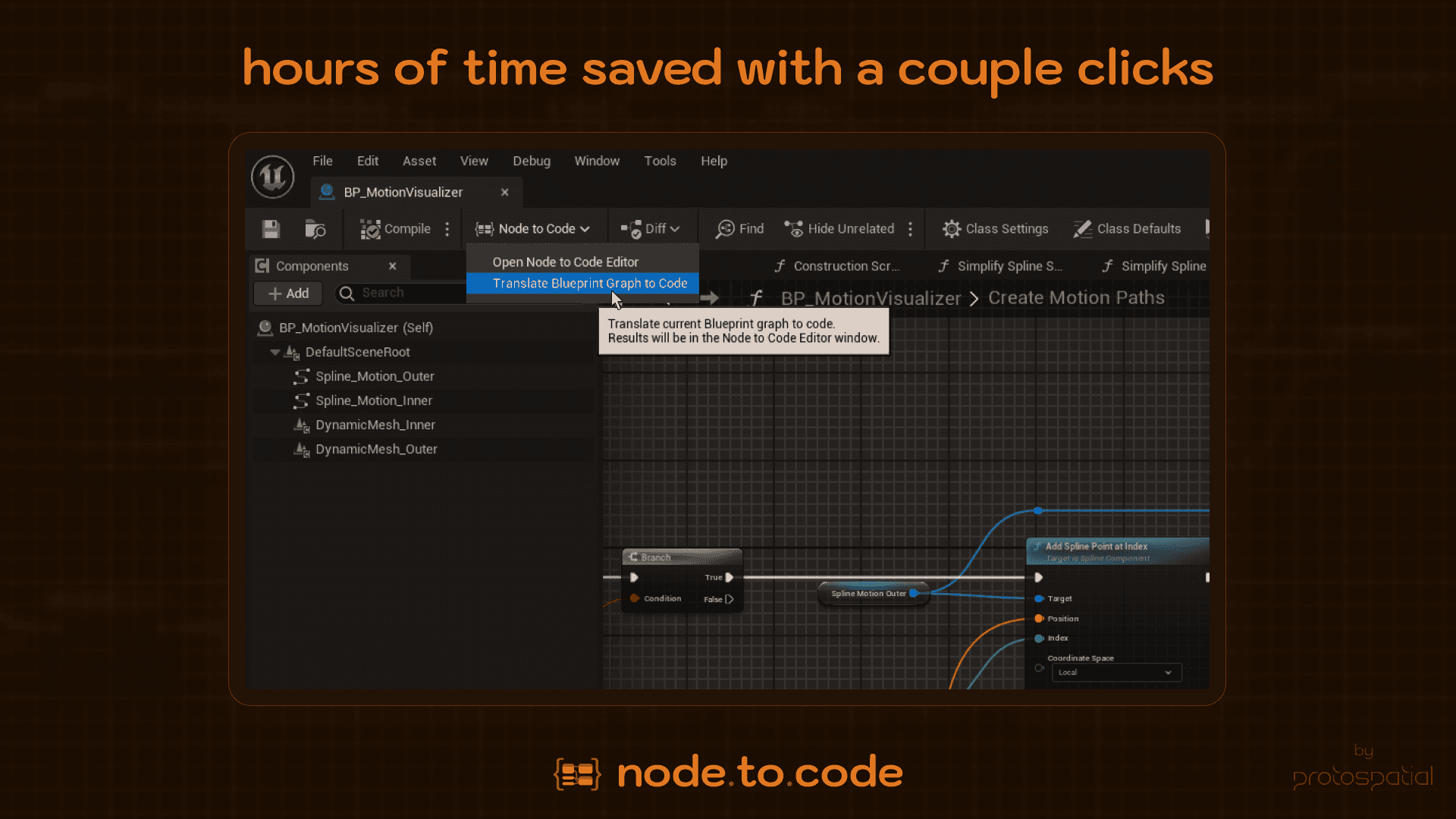
The AI Spark & Custom Serialization
My journey into Large Language Models (LLMs) started around 2017, growing from fascination to active experimentation with OpenAI's APIs by 2021. My first thought was always, "How can this enhance my Unreal workflows?" Early attempts to feed Blueprint's native plaintext serialization directly to models like GPT-3.5 were… humbling. The format was simply too verbose; even a simple 7-node function could consume a massive token count and yield garbled, unusable C++ code.
Even as models improved (Claude, GPT-4, local models via Ollama), the fundamental inefficiency remained. That's when the idea hit: What if I created an intermediary serialization format? Something compact, semantically rich, and optimized for LLMs, capturing the core logic while stripping unnecessary editor metadata.
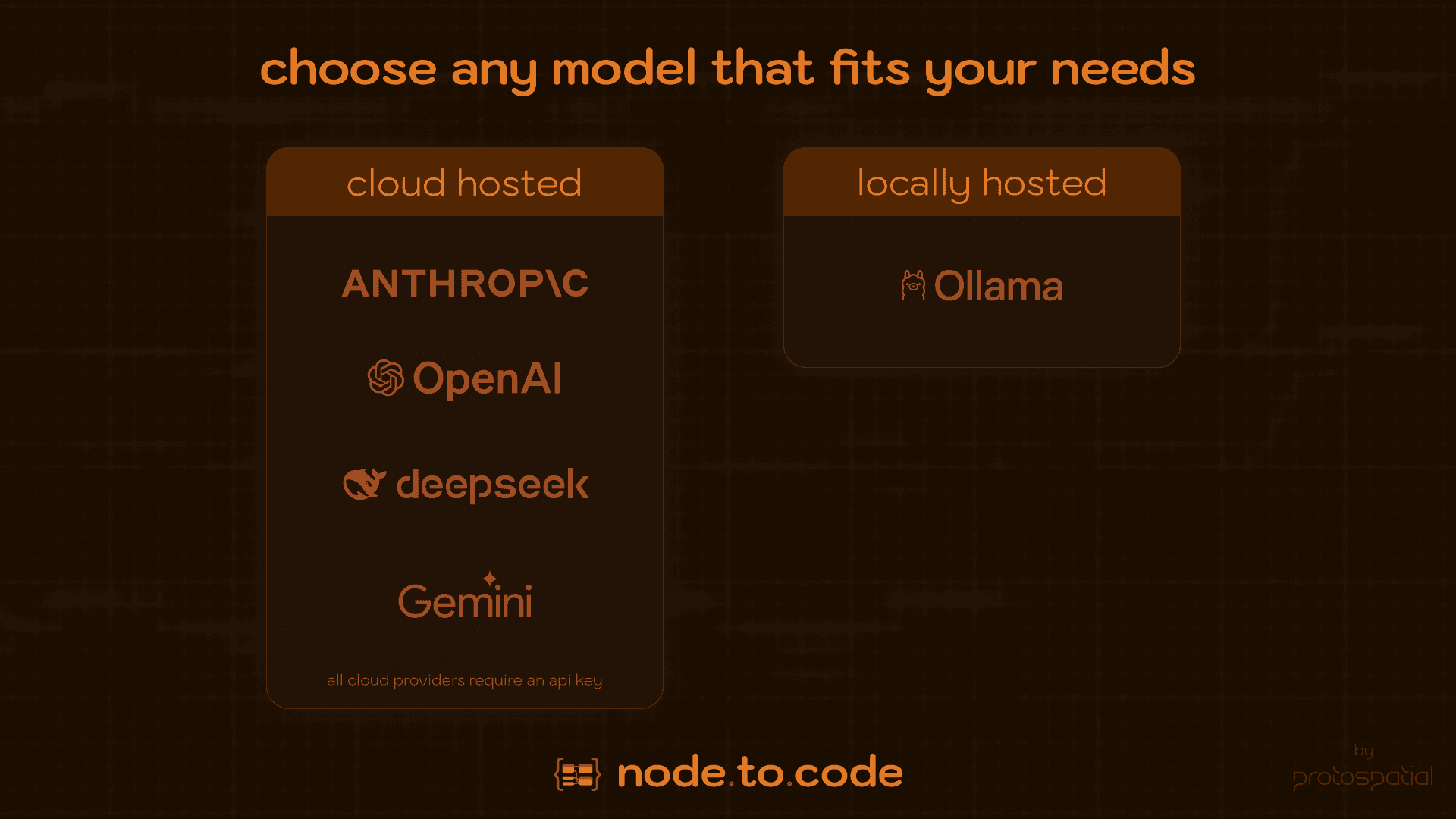
This custom JSON schema proved transformative. It typically reduced token counts by 60-90% compared to UE's native format, making translations faster and cheaper. More importantly, LLMs seemed to understand this structured format significantly better, producing far more accurate C++ translations that respected UE patterns and macros. I tested this with various providers – Anthropic's Claude models excelled at code generation and UE specifics, OpenAI's models were great reasoners, and even local models via Ollama could handle basic translations effectively.
This wasn't about replacing Blueprints or C++, but building a bridge between them.
My Role: Architecting the Bridge
Building Node to Code involved architecting and implementing several key systems from the ground up:
Core Concept & Vision: Identified the core problem based on extensive personal experience and conceived the LLM-based translation approach with custom serialization as the solution.
Blueprint Analysis & Collection: Developed the core logic (FN2CNodeCollector, FN2CNodeTypeHelper) to deeply parse Blueprint graphs (UEdGraph), analyzing K2Nodes and K2Pins to extract execution/data flows, metadata, variable/function references, comments, and handle over 100 native node types, including edge cases like Knots/Reroutes.
Custom Serialization Format: Designed and implemented the specialized, LLM-optimized JSON schema that drastically reduces token count (60-90%) while preserving all critical logical information for accurate translation.
Translation Depth Management: Architected the recursive system that allows Node to Code to intelligently traverse nested user-created functions, collapsed graphs, macros, event bindings (CreateDelegate), and math expressions up to a configurable depth (0-5), enabling translation of entire features.

LLM Provider Integration: Designed a flexible, provider-agnostic interface (IN2CLLMService) and implemented concrete services for multiple providers (Anthropic Claude, OpenAI, Google Gemini, DeepSeek, local Ollama), handling their unique API requirements, payload formatting, authentication, and error patterns.
Prompt Engineering & Contextualization: Developed the prompt management system (N2CSystemPromptManager) to deliver tailored instructions to the LLM based on the target language (C++, C#, Python, JS, Swift). Crucially, I implemented the Reference Source File system, allowing users to provide existing .h/.cpp files (from their project, engine, or plugins) to guide the LLM on coding style, patterns, and relevant class structures, significantly improving output quality and coherence.

Response Processing & Data Structuring: Created the robust response parsing system (UN2CResponseParserBase and provider-specific parsers) to handle diverse LLM output formats (including stripping "thinking" tags from reasoning models) and transform the JSON response into structured C++ objects (FN2CTranslationResponse, FN2CGraphTranslation) containing declarations, implementations, and crucial implementation notes.
UI/UX Design & Implementation: Designed and built the Node to Code editor window using a hybrid approach: a custom Slate widget (SN2CCodeEditor) for the core text editor with syntax highlighting, integrated within a polished Editor Utility Widget (UMG) for the overall interface, including the translation browser, settings, and data-driven theming, ensuring a familiar and native Unreal Engine feel.

Beyond Translation: Unexpected Discoveries
Using Node to Code daily revealed benefits I hadn't initially anticipated. It became a powerful C++ learning tool; seeing my own Blueprint logic translated provided immediate, contextual understanding of C++ patterns and UE APIs far better than generic tutorials. It also turned into a documentation generator; instead of messy screenshots, I could generate clean code snippets to explain logic in technical documents or team discussions. This significantly improved team workflows, enabling clearer communication between Blueprint creators and C++ engineers, facilitating code reviews, and accelerating knowledge transfer.

The Practical Side
Node to Code shines when optimizing performance-critical Blueprints (heavy loops, large datasets, tick-based logic), scaling complex systems that become unwieldy, or bridging the gap between visual scripting and code for learning and documentation. However, it's not a magic bullet. For simple, event-driven Blueprints, the overhead might not be worth it. Highly specialized systems (low-level rendering, complex algorithms) are often best written directly in C++. Always test translated code thoroughly, especially in critical systems, and review the LLM's implementation notes – they often contain valuable insights.
Closing Thoughts
Node to Code began as a tool to scratch my own itch, born from the friction between Blueprint's rapid iteration and C++'s performance needs. It has evolved into a powerful bridge, aiming to enhance, not replace, the workflows we use in Unreal Engine. By leveraging AI as an augmentation, not a replacement, my hope is that tools like this can empower creators to overcome technical hurdles more easily and focus on bringing their visions to life. It's exciting to think about how the community will use and shape this technology moving forward.
Explore Node to Code
GitHub Repository: https://github.com/protospatial/NodeToCode
Documentation Wiki: https://github.com/protospatial/NodeToCode/wiki
Fab Marketplace: https://www.fab.com/listings/29955a71-cd04-4111-ac43-6a0264429ce6
Discord Community: https://www.protospatial.com/support
Development Roadmap: https://trello.com/b/iPOyaSvb
Support the Project
Sponsor on GitHub: https://github.com/sponsors/NCMcClure
Buy Me a Coffee: https://www.buymeacoffee.com/protospatial
year
2025
timeframe
1 month
tools
Unreal Engine 5, Rider, Aider, Figma, GitHub
category
Personal Project
01
see also



















